Amazon's A9 and Alexa appear to have switched from using Google to power their web search to using Microsoft's Windows Live Search (aka MSN Search).
I wonder if this is a sign of increasing collaboration between the two Seattle area companies.
[via Google Operating System, John Battelle, Nicholas Carr, and Threadwatch]
Update: Seattle PI reporter Todd Bishop confirms the story.
Update: MSN Search PM Erik Selberg says, "It's a step towards more collaboration between Amazon and Microsoft. It's painfully clear to everyone that the power of Google AdWords and AdSense are on a collision course for Amazon and eBay .... [Google] is a huge threat to Amazon's business."
Update: Danny Sullivan points out that Google ads also have been removed.
Sunday, April 30, 2006
Early Amazon: Auctions
In March of 1999, Amazon.com launched an auction site to compete with eBay.
Behind the scenes, this was a herculean effort. People from around the company were pulled off their projects. The entire Auction site, with all the features of eBay and more, was built from scratch. It was designed, architected, developed, tested, and launched in under three months.
In addition to a fair amount of architecture work, I had the task of designing and coding the account system, everything around registration and login of buyers and sellers.
Rather boring stuff, I thought, and perhaps that was tempting fate. Just a couple weeks from launch, Jeff Bezos decided to reverse a fundamental design decision that required rewriting almost the entire account system.
I was told about Bezos' decision late one Friday afternoon. I designed the new system that Friday evening. I came in at 7am the next morning and started a frenzy of coding. I left again at 11pm, then came back at 7am that Sunday morning. At 6pm Sunday evening, blurry-eyed, I had done all the testing I could stand to do.
The hastily written code seemed solid, but I feared that was wishful thinking on my part. Perhaps to lower expectations, perhaps just crazed from sleep deprivation, Sunday evening I committed to the source repository what I called the "Share My Pain" release.
The next day, to my pleasant surprise, few bugs were found in the new code. Those minor pains and the remaining issues elsewhere were quickly resolved. Amazon Auctions somehow launched on time, an entire business built in three short months.
Amazon Auctions was designed to be a frontal assault on eBay, reproducing everything they had in one fell swoop. Amazon thought its tens of millions of customers would immediately adapt to auctions and small businesses would flock to our site. It was an aggressive move that was foolishly arrogant.
When the site launched, it was technically superior to eBay's, faster, better search, and several new useful features. The inventory was reasonable, but not large.
Over the following months, the site did not grow as rapidly as some at Amazon optimistically projected. Amazon customers turned out to be quite timid about exploring the auction site, fearful of the lack of guarantees and customer service, unattracted to the idea of bidding.
Amazon Auctions stalled. Sellers moved away. Eventually, Amazon just gave up on it. While Amazon Auctions occasionally twitches in its sad resting spot on the current Amazon site, it is all but dead now.
It did not have to be that way. We were building this from scratch, and there was a lively debate inside Amazon about what we should build.
The debate fell into three camps. The main group argued that we should duplicate eBay and assault them head on.
The other two groups wanted a narrower focus. One (which included me) argued that we should optimize for medium-sized and large businesses instead of small sellers, stealing away the top end of the market. The other argued that we should focus on dominating auctions of books, music, and video -- the core product lines of Amazon -- and leave selling beanie babies and other oddities to eBay.
The "head on assault" crowd won, and then ultimately lost. Over the last several years, Amazon eventually migrated its strategy to versions of what the other two camps advocated. Amazon now allows third party sellers (mostly medium and large businesses) to sell items on its product pages (not collectibles and oddities).
Perhaps the only way Amazon could develop its current third party selling strategy was to experiment and learn along this circuitous path. But I cannot help but think that it could have gotten to this place faster had we been more humble back in 1999.
Behind the scenes, this was a herculean effort. People from around the company were pulled off their projects. The entire Auction site, with all the features of eBay and more, was built from scratch. It was designed, architected, developed, tested, and launched in under three months.
In addition to a fair amount of architecture work, I had the task of designing and coding the account system, everything around registration and login of buyers and sellers.
Rather boring stuff, I thought, and perhaps that was tempting fate. Just a couple weeks from launch, Jeff Bezos decided to reverse a fundamental design decision that required rewriting almost the entire account system.
I was told about Bezos' decision late one Friday afternoon. I designed the new system that Friday evening. I came in at 7am the next morning and started a frenzy of coding. I left again at 11pm, then came back at 7am that Sunday morning. At 6pm Sunday evening, blurry-eyed, I had done all the testing I could stand to do.
The hastily written code seemed solid, but I feared that was wishful thinking on my part. Perhaps to lower expectations, perhaps just crazed from sleep deprivation, Sunday evening I committed to the source repository what I called the "Share My Pain" release.
The next day, to my pleasant surprise, few bugs were found in the new code. Those minor pains and the remaining issues elsewhere were quickly resolved. Amazon Auctions somehow launched on time, an entire business built in three short months.
Amazon Auctions was designed to be a frontal assault on eBay, reproducing everything they had in one fell swoop. Amazon thought its tens of millions of customers would immediately adapt to auctions and small businesses would flock to our site. It was an aggressive move that was foolishly arrogant.
When the site launched, it was technically superior to eBay's, faster, better search, and several new useful features. The inventory was reasonable, but not large.
Over the following months, the site did not grow as rapidly as some at Amazon optimistically projected. Amazon customers turned out to be quite timid about exploring the auction site, fearful of the lack of guarantees and customer service, unattracted to the idea of bidding.
Amazon Auctions stalled. Sellers moved away. Eventually, Amazon just gave up on it. While Amazon Auctions occasionally twitches in its sad resting spot on the current Amazon site, it is all but dead now.
It did not have to be that way. We were building this from scratch, and there was a lively debate inside Amazon about what we should build.
The debate fell into three camps. The main group argued that we should duplicate eBay and assault them head on.
The other two groups wanted a narrower focus. One (which included me) argued that we should optimize for medium-sized and large businesses instead of small sellers, stealing away the top end of the market. The other argued that we should focus on dominating auctions of books, music, and video -- the core product lines of Amazon -- and leave selling beanie babies and other oddities to eBay.
The "head on assault" crowd won, and then ultimately lost. Over the last several years, Amazon eventually migrated its strategy to versions of what the other two camps advocated. Amazon now allows third party sellers (mostly medium and large businesses) to sell items on its product pages (not collectibles and oddities).
Perhaps the only way Amazon could develop its current third party selling strategy was to experiment and learn along this circuitous path. But I cannot help but think that it could have gotten to this place faster had we been more humble back in 1999.
Make it easy
Paul Boutin in Slate writing about YouTube: "The secret to success is to make everything one-button easy, then get out of the way."
Friday, April 28, 2006
Microsoft is building a Google cluster
Benjamin Romano at the Seattle Times reports that Microsoft "plans to plow perhaps $2 billion more than expected -- a meaningful sum even for the world's largest software company -- into new technologies, marketing for its most significant wave of product launches in a decade, and the fight for online supremacy against Yahoo! and Google."
This spending is an explicit part of Microsoft's strategy in the search war. In a Fortune article, Microsoft CTO Ray Ozzie said that the cost of building these massive online clusters is a huge barrier to entry and that "the people who could build a viable [Web] services infrastructure of scale are companies that have both the will and the capacity to invest staggering amounts of money."
Microsoft is trying to build a Google-sized cluster, belatedly recognizing that massive computing resources are "major force multipliers" for those who have them and an insurmountable barrier for those that do not.
As Ozzie said, few others have the resources to build this massive online computing infrastructure. Who else can build, maintain, and exploit a cluster of millions of servers? Who else can spend the billions required? Not Amazon. Not Ask. Not any venture-funded startup. Probably not Yahoo.
The search war is now an arms race. The buildup in computing power for the battles ahead will be remarkable to watch.
This spending is an explicit part of Microsoft's strategy in the search war. In a Fortune article, Microsoft CTO Ray Ozzie said that the cost of building these massive online clusters is a huge barrier to entry and that "the people who could build a viable [Web] services infrastructure of scale are companies that have both the will and the capacity to invest staggering amounts of money."
Microsoft is trying to build a Google-sized cluster, belatedly recognizing that massive computing resources are "major force multipliers" for those who have them and an insurmountable barrier for those that do not.
As Ozzie said, few others have the resources to build this massive online computing infrastructure. Who else can build, maintain, and exploit a cluster of millions of servers? Who else can spend the billions required? Not Amazon. Not Ask. Not any venture-funded startup. Probably not Yahoo.
The search war is now an arms race. The buildup in computing power for the battles ahead will be remarkable to watch.
Thursday, April 27, 2006
Finding and discovering
A Jan 2006 CACM article out of Microsoft Research offers a nice overview of the Stuff I've Seen project.
One particularly interesting part of the article explores how personalization complements search. Some excerpts:
Personalization helps when you do not know what is out there. Personalization surfaces interesting items you did not know about and may not have found on your own.
Search is finding. Personalization is discovering.
One particularly interesting part of the article explores how personalization complements search. Some excerpts:
Implicit Query ... analyzes the email message the user is looking at and extracts important words from the body, subject, sender, and recipient fields. These words are automatically used in a query ... and the results are shown as a side panel attached to the current message.Search helps when you know what is out there and can easily say what you want.
We thought IQ would be helpful in sparing users the effort of generating queries, and indeed it is.
But many people have also reported an unanticipated benefit of finding information, especially when they completely forgot they had anything related and would never have generated an explicit search on their own.
Personalization helps when you do not know what is out there. Personalization surfaces interesting items you did not know about and may not have found on your own.
Search is finding. Personalization is discovering.
Seeking the talent in the crowd
A great post by Nicholas Carr rips into the surprisingly popular idea that diamonds will appear if you simply mash enough steaming piles of user-generated content together.
Some selected excerpts:
There may be wisdom in that crowd. There is also a lot of noise. Separating the wisdom from the noise is the real challenge.
See also my previous post, "Getting the crap out of user-generated content".
Some selected excerpts:
Although wikis and other Web 2.0 platforms for the creation of content are often described in purely egalitarian terms - as the products of communities of equals - that's just a utopian fantasy.As I have said before, summing collective ignorance isn't going to create wisdom. Take a majority vote from people who don't know the answer, and you're not going to get the right answer.
Quality ... hinges not just, or even primarily ... on the number of contributors ... [but] on the talent of the contributors.
When you look deeply into Wikipedia, beyond the shiny surface of "community," you see that [it] is actually ... more a product of conflict than of collaboration: It's an endless struggle by a few talented contributors to clean up the mess left by the numbskull horde.
There may be wisdom in that crowd. There is also a lot of noise. Separating the wisdom from the noise is the real challenge.
See also my previous post, "Getting the crap out of user-generated content".
Wednesday, April 26, 2006
Early Amazon: Just do it
Later, Amazon thoroughly embraced the reckless passion of innovation. "Just do it" became a rallying cry.
In typical display of Bezos silliness, "just do it" was codified in the "Just do it" awards. Recipients were brought up in front of the entire company and given an old, used Nike shoe.
I got a couple of these -- including one for shopping cart recommendations -- but, after moving to Stanford and back to Seattle, the old, stinky, mismatched shoes have long been lost.
What was not lost was the sense of pride. I was proud to have gotten that crappy old shoe.
Of course, it was not the prize itself that mattered. It was the recognition. It was that someone had noticed and said thanks. That was what I wanted.
Recently, I have had some interesting debates about management goo with a couple different friends who work at two large, well-known Internet companies. One thing we were talking about was compensation strategies.
My opinion has swung 180 degrees on compensation in the last few years. I used to be a huge fan of pay for performance. Salaries, I thought, should be varied by how well you do and what you have done.
Now, I believe that pay and perks should be high but basically flat; exceptional work should be recognized in other ways.
What changed my mind?
While merit pay sounds like a great idea in theory, it seems it never works in any large organization. It appears to be impossible to do fairly -- politics and favoritism always enter the mix -- and, even if it could be done fairly, it never makes people happy.
A recent example of this is the news about poor morale at Microsoft because of their elaborate performance review and merit pay system. It is seen as unfair. It makes everyone unhappy. It just does not work.
Instead, compensation should be high but basically flat. Merit rewards should focus on non-monetary compensation. Maybe even an stinky old shoe.
That used shoe was worth far more than it might appear. It was a thank you. It was recognition. These are things valued by many, but offered far too rarely.
In typical display of Bezos silliness, "just do it" was codified in the "Just do it" awards. Recipients were brought up in front of the entire company and given an old, used Nike shoe.
I got a couple of these -- including one for shopping cart recommendations -- but, after moving to Stanford and back to Seattle, the old, stinky, mismatched shoes have long been lost.
What was not lost was the sense of pride. I was proud to have gotten that crappy old shoe.
Of course, it was not the prize itself that mattered. It was the recognition. It was that someone had noticed and said thanks. That was what I wanted.
Recently, I have had some interesting debates about management goo with a couple different friends who work at two large, well-known Internet companies. One thing we were talking about was compensation strategies.
My opinion has swung 180 degrees on compensation in the last few years. I used to be a huge fan of pay for performance. Salaries, I thought, should be varied by how well you do and what you have done.
Now, I believe that pay and perks should be high but basically flat; exceptional work should be recognized in other ways.
What changed my mind?
While merit pay sounds like a great idea in theory, it seems it never works in any large organization. It appears to be impossible to do fairly -- politics and favoritism always enter the mix -- and, even if it could be done fairly, it never makes people happy.
A recent example of this is the news about poor morale at Microsoft because of their elaborate performance review and merit pay system. It is seen as unfair. It makes everyone unhappy. It just does not work.
Instead, compensation should be high but basically flat. Merit rewards should focus on non-monetary compensation. Maybe even an stinky old shoe.
That used shoe was worth far more than it might appear. It was a thank you. It was recognition. These are things valued by many, but offered far too rarely.
Microsoft's new Wallop startup
John Cook from the Seattle PI reports that Microsoft has spun out a 12-person social networking startup from Microsoft Research called Wallop.
From Microsoft's press release:
Microsoft Research has published a couple papers that appear to cover some of the technology behind Wallop, "Wallop: Designing Social Software for Co-located Social Networks" (PDF) and "Personal Map: Automatically Modeling the User's Online Social Network" (PDF).
From the papers, it sounds like they build a social network implicitly from communications (e-mails sent, instant messaging, etc.) between people.
I have been more interested in seeing this data used to prioritize contacts and incoming messages, like MSR's Priorities and Inner Circle projects, but exposing the social network derived from this data is also clever and useful.
See also Kari Lynn Dean's Nov 2003 Wired article on Wallop.
From Microsoft's press release:
Wallop solves the problems plaguing current social networking technologies .... Wallop developed a unique set of algorithms that respond to social interactions to automatically build and maintain a person's social network.I like this idea. Automatically building the network means less work for users. It means the network is less likely to become stale over time. It increases the likelihood that people will start using it and keep using it.
Microsoft Research has published a couple papers that appear to cover some of the technology behind Wallop, "Wallop: Designing Social Software for Co-located Social Networks" (PDF) and "Personal Map: Automatically Modeling the User's Online Social Network" (PDF).
From the papers, it sounds like they build a social network implicitly from communications (e-mails sent, instant messaging, etc.) between people.
I have been more interested in seeing this data used to prioritize contacts and incoming messages, like MSR's Priorities and Inner Circle projects, but exposing the social network derived from this data is also clever and useful.
See also Kari Lynn Dean's Nov 2003 Wired article on Wallop.
Tuesday, April 25, 2006
Early Amazon: Shopping cart recommendations
I have talked about a couple fun projects ([1] [2]) I did at Amazon even though I was supposed to be working on other things. This story is more extreme, a project I was explicitly forbidden to do and did anyway.
I loved the idea of making recommendations based on the items in your Amazon shopping cart. Add a couple things, see what pops up. Add a couple more, see what changes.
The idea of recommending items at checkout is nothing new. Grocery stories put candy and other impulse buys in the checkout lanes. Hardware stores put small tools and gadgets near the register.
But here we had an opportunity to personalize impulse buys. It is as if the rack near the checkout lane peered into your grocery cart and magically rearranged the candy based on what you are buying.
Health food in your cart? Let's bubble that organic dark chocolate bar to the top of the impulse buys. Steaks and soda? Get those snack-sized potato chip bags up there right away.
I hacked up a prototype. On a test site, I modified the Amazon.com shopping cart page to recommend other items you might enjoy adding to your cart. Looked pretty good to me. I started showing it around.
While the reaction was positive, there was some concern. In particular, a marketing senior vice-president was dead set against it. His main objection was that it might distract people away from checking out -- it is true that it is much easier and more common to see customers abandon their cart at the register in online retail -- and he rallied others to his cause.
At this point, I was told I was forbidden to work on this any further. I was told Amazon was not ready to launch this feature. It should have stopped there.
Instead, I prepared the feature for an online test. I believed in shopping cart recommendations. I wanted to measure the sales impact.
I heard the SVP was angry when he discovered I was pushing out a test. But, even for top executives, it was hard to block a test. Measurement is good. The only good argument against testing would be that the negative impact might be so severe that Amazon couldn't afford it, a difficult claim to make. The test rolled out.
The results were clear. Not only did it win, but the feature won by such a wide margin that not having it live was costing Amazon a noticeable chunk of change. With new urgency, shopping cart recommendations launched.
An interesting story, I suppose, but what lessons are to be seen in this?
I do know that, in some organizations, challenging an SVP would be a fatal mistake, right or wrong. When I was at Stanford Business School, I had many occasions to debate those that favored command-and-control style management and learn more about their beliefs.
Those that favor command-and-control, top-down structures seemed to argue that it matters little which hill you charge, as long as you all charge the same hill. Loyalty and obedience, they said, matter more than competence. As they see it, for any organization, chaos is the enemy.
In my experience, innovation can only come from the bottom. Those closest to the problem are in the best position to solve it. I believe any organization that depends on innovation must embrace chaos. Loyalty and obedience are not your tools; you must use measurement and objective debate to separate the good from the bad.
At the time, Amazon was certainly chaotic, but I suspect I was taking a risk by ignoring commands from above. As good as Amazon was, it did not yet have a culture that fully embraced measurement and debate.
I think building this culture is the key to innovation. Creativity must flow from everywhere. Whether you are a summer intern or the CTO, any good idea must be able to seek an objective test, preferably a test that exposes the idea to real customers.
Everyone must be able to experiment, learn, and iterate. Position, obedience, and tradition should hold no power. For innovation to flourish, measurement must rule.
I loved the idea of making recommendations based on the items in your Amazon shopping cart. Add a couple things, see what pops up. Add a couple more, see what changes.
The idea of recommending items at checkout is nothing new. Grocery stories put candy and other impulse buys in the checkout lanes. Hardware stores put small tools and gadgets near the register.
But here we had an opportunity to personalize impulse buys. It is as if the rack near the checkout lane peered into your grocery cart and magically rearranged the candy based on what you are buying.
Health food in your cart? Let's bubble that organic dark chocolate bar to the top of the impulse buys. Steaks and soda? Get those snack-sized potato chip bags up there right away.
I hacked up a prototype. On a test site, I modified the Amazon.com shopping cart page to recommend other items you might enjoy adding to your cart. Looked pretty good to me. I started showing it around.
While the reaction was positive, there was some concern. In particular, a marketing senior vice-president was dead set against it. His main objection was that it might distract people away from checking out -- it is true that it is much easier and more common to see customers abandon their cart at the register in online retail -- and he rallied others to his cause.
At this point, I was told I was forbidden to work on this any further. I was told Amazon was not ready to launch this feature. It should have stopped there.
Instead, I prepared the feature for an online test. I believed in shopping cart recommendations. I wanted to measure the sales impact.
I heard the SVP was angry when he discovered I was pushing out a test. But, even for top executives, it was hard to block a test. Measurement is good. The only good argument against testing would be that the negative impact might be so severe that Amazon couldn't afford it, a difficult claim to make. The test rolled out.
The results were clear. Not only did it win, but the feature won by such a wide margin that not having it live was costing Amazon a noticeable chunk of change. With new urgency, shopping cart recommendations launched.
An interesting story, I suppose, but what lessons are to be seen in this?
I do know that, in some organizations, challenging an SVP would be a fatal mistake, right or wrong. When I was at Stanford Business School, I had many occasions to debate those that favored command-and-control style management and learn more about their beliefs.
Those that favor command-and-control, top-down structures seemed to argue that it matters little which hill you charge, as long as you all charge the same hill. Loyalty and obedience, they said, matter more than competence. As they see it, for any organization, chaos is the enemy.
In my experience, innovation can only come from the bottom. Those closest to the problem are in the best position to solve it. I believe any organization that depends on innovation must embrace chaos. Loyalty and obedience are not your tools; you must use measurement and objective debate to separate the good from the bad.
At the time, Amazon was certainly chaotic, but I suspect I was taking a risk by ignoring commands from above. As good as Amazon was, it did not yet have a culture that fully embraced measurement and debate.
I think building this culture is the key to innovation. Creativity must flow from everywhere. Whether you are a summer intern or the CTO, any good idea must be able to seek an objective test, preferably a test that exposes the idea to real customers.
Everyone must be able to experiment, learn, and iterate. Position, obedience, and tradition should hold no power. For innovation to flourish, measurement must rule.
Monday, April 24, 2006
Using the desktop to improve search
The search experience is primitive, one box gazing at us from an HTML form. It hasn't changed much since 1994.
But is it really natural to go to a web browser to find information? Or should information be readily available from the desktop and sensitive to the context of your current task?
I expect we some day will see information retrieval become a natural part of workflow. Search will be integrated into the desktop.
Tasks will become more of a collaborative process. Your focus will remain on your task, but the computer will become your assistant, bringing relevant information closer to you should you need to reach for it.
Microsoft Researcher Susan Dumais recently said:
At Microsoft Research, the Stuff I've Seen project seeks to allow rapid access to any information you have seen before on your computer. Implicit Query tries to surface relevant information on your desktop without an explicit search. Search personalization targets search results using additional data about the user and the context of the search. Priorities and The Scope intend to focus your attention on important information and avoid unnecessary interruptions. Scalable Fabric and Data Mountain offer task-focused advanced user interfaces for managing your information and work, interfaces that are impossible to reproduce in a web browser.
If these can be combined, refined, finished, and moved into the Windows desktop, Microsoft may be able to build a task-focused, advanced user interface that organizes your information, pays attention to what you are doing to help you find what you need, and surfaces additional information and alerts only when it is important and relevant.
It would be an experience impossible to reproduce in a web browser, a jump beyond the 1994, one-box search interface we still live with today.
But is it really natural to go to a web browser to find information? Or should information be readily available from the desktop and sensitive to the context of your current task?
I expect we some day will see information retrieval become a natural part of workflow. Search will be integrated into the desktop.
Tasks will become more of a collaborative process. Your focus will remain on your task, but the computer will become your assistant, bringing relevant information closer to you should you need to reach for it.
Microsoft Researcher Susan Dumais recently said:
We can make it easier for [people] to get results without leaving the application they're in ... Search is not the end goal. We want to show people results in context and help them integrate those results into whatever they're doing.With their control of the desktop, Microsoft is in an ideal position to drive toward this future.
At Microsoft Research, the Stuff I've Seen project seeks to allow rapid access to any information you have seen before on your computer. Implicit Query tries to surface relevant information on your desktop without an explicit search. Search personalization targets search results using additional data about the user and the context of the search. Priorities and The Scope intend to focus your attention on important information and avoid unnecessary interruptions. Scalable Fabric and Data Mountain offer task-focused advanced user interfaces for managing your information and work, interfaces that are impossible to reproduce in a web browser.
If these can be combined, refined, finished, and moved into the Windows desktop, Microsoft may be able to build a task-focused, advanced user interface that organizes your information, pays attention to what you are doing to help you find what you need, and surfaces additional information and alerts only when it is important and relevant.
It would be an experience impossible to reproduce in a web browser, a jump beyond the 1994, one-box search interface we still live with today.
Sunday, April 23, 2006
Google SMS and search as a dialogue
Rudy Schusteritsch and Kerry Rodden at Google wrote an interesting CHI 2005 short paper, "Mobile Search with Text Messages: Designing the User Experience for Google SMS", that discusses some of the constraints and challenges in building Google SMS.
Most interesting to me were the tidbits on how many users seemed to expect Google SMS not to work like a one-shot search, but more as a dialogue. Some excerpts:
This does suggest an alternative model for mobile search using SMS. Perhaps the search should be iterative. For example, I could imagine this chain of SMS messages between me and a search engine:
But, the user study seemed to suggest that Google SMS users do expect more of a dialogue model. While we can train users out of that expectation, I think the dialogue model has advantages for helping people discover and narrow down on what they want.
I believe this is also true for regular web search. Current search engines treat each search as independent, but that is not how people use search engines.
When I need to find something, I start with one search. If I am not satisfied with those results, I refine my query, changing it to something slightly different. If that doesn't get me what I want, I change it again.
I am repeatedly refining my search query, trying to find the information I need. But current search engines ignore this stream of related queries, this dialogue, instead treating each search as independent.
In both mobile search and web search, I think there is an opportunity for techniques that focus explicitly on this kind of refinement process, bringing all the information from the past and present to bear.
I think search should be a dialogue, going on for as long as it takes to help people find what they need.
Most interesting to me were the tidbits on how many users seemed to expect Google SMS not to work like a one-shot search, but more as a dialogue. Some excerpts:
At present, SMS is primarily used for 1-to-1 communication; Google SMS repurposes it to enable mobile search. We expected that this might be confusing to users, requiring them to adjust their conceptual model of the technology ....People at first expected Google SMS to work like normal SMS, like a conversation. They appeared to expect a back-and-forth of text messages, narrowing in on the information desired.
Most [users] had some initial problems understanding how it could be used for search. For example, one experienced SMS user wondered at first whether a Google employee would receive their query and reply with an answer ....
Several users started a product search task by sending a message like "shopping", expecting to enter a mode that would cause their subsequent messages to be interpreted as product searches. They were confused to receive an error message in return, telling them that their query had no results.
This does suggest an alternative model for mobile search using SMS. Perhaps the search should be iterative. For example, I could imagine this chain of SMS messages between me and a search engine:
Me: sushiOr this conversation:
Google SMS: A sushi restaurant in Seattle? Blue C Sushi in Fremont is popular. Directions? A recommendation for sushi somewhere else?
Me: downtown
Google SMS: Saito's at 2nd and Lenoa? Red Fin at 6th and Stewart? Both highly rated.
Me: saito
Google SMS: Saito's Japanese Cafe & Bar, 2120 2nd Ave, Seattle (206) 728-1333
Me: price ipodI am glossing over some hard issues here. How would the system determine that a thread has ended and a new one begun? How would we reliably disambiguate and intelligently respond to iterative queries? What can we do to avoid searcher frustration if we guess wrong about user intent? How do we respond clearly in less than 160 characters in the general case?
Google SMS: Average price, 60G iPod, $383. Lowest price, $344, at PCMall.
Me: 30g
Google SMS: Average price, 30G iPod, $322. Lowest price, $282, at Amazon.
Me: at apple
Google SMS: Apple.com, 30G iPod, $299 + tax with free shipping.
But, the user study seemed to suggest that Google SMS users do expect more of a dialogue model. While we can train users out of that expectation, I think the dialogue model has advantages for helping people discover and narrow down on what they want.
I believe this is also true for regular web search. Current search engines treat each search as independent, but that is not how people use search engines.
When I need to find something, I start with one search. If I am not satisfied with those results, I refine my query, changing it to something slightly different. If that doesn't get me what I want, I change it again.
I am repeatedly refining my search query, trying to find the information I need. But current search engines ignore this stream of related queries, this dialogue, instead treating each search as independent.
In both mobile search and web search, I think there is an opportunity for techniques that focus explicitly on this kind of refinement process, bringing all the information from the past and present to bear.
I think search should be a dialogue, going on for as long as it takes to help people find what they need.
Friday, April 21, 2006
100k+ new servers per quarter at Google?
Over in the comments of Paul Kedrosky's blog, Paul and I were talking about Google's $345M capital expenditures in Q1 2006.
Assuming that capex is mainly for buying commodity servers, that works out to roughly 100k-200k new servers in Q1 2006. Paul says he thinks the lower end of that range, 100k or so, is more likely.
Either way, wowsers. That is quite a cluster they are building.
See also my previous posts, "200k+ servers at Google and growing" and "In a world with infinite storage, bandwidth, and CPU power".
See also my previous posts, "Google Sawzall" and "Google Cluster Architecture".
Update: Two months later, John Markoff and Saul Hansell at the New York Times report that "the best guess is that Google now has more than 450,000 servers spread over at least 25 locations around the world." [via Don Dodge]
Assuming that capex is mainly for buying commodity servers, that works out to roughly 100k-200k new servers in Q1 2006. Paul says he thinks the lower end of that range, 100k or so, is more likely.
Either way, wowsers. That is quite a cluster they are building.
See also my previous posts, "200k+ servers at Google and growing" and "In a world with infinite storage, bandwidth, and CPU power".
See also my previous posts, "Google Sawzall" and "Google Cluster Architecture".
Update: Two months later, John Markoff and Saul Hansell at the New York Times report that "the best guess is that Google now has more than 450,000 servers spread over at least 25 locations around the world." [via Don Dodge]
SIGIR in Seattle
The ACM SIGIR 2006 conference will be here in Seattle August 6-11 at the lovely University of Washington campus.
Registration starts soon. Should be a good time.
[via Erik Selberg]
Update: I will be at the conference and on the AIRWeb panel. Looking forward to it!
Registration starts soon. Should be a good time.
[via Erik Selberg]
Update: I will be at the conference and on the AIRWeb panel. Looking forward to it!
Thursday, April 20, 2006
New relevance rank in Google Scholar
Dejan Perkovic has the post on the official Google blog about an impressive new relevance rank feature in Google Scholar:
On a search for [collaborative filtering], the first results appropriately are GroupLens papers, followed by an excellent Breese and Heckerman paper.
On a search for [web search], the Sergey Brin and Larry Page's paper gets the top result, followed by a paper from Steve Lawrence.
Great stuff. Very cool and very useful.
Update: As Dejan wrote in an update to his post and confirmed to me by e-mail and OR pointed out in the comments, the new feature is the "Recent articles" relevance rank. The "All articles" relevance rank (which I linked to in my examples above) is unchanged.
Hearing this, I think it is likely this feature is a response to the recent launch of Windows Live Academic and "order by date" features in that service. The Google Scholar "Recent articles" ranking is more complicated than just ordering by date, but it is unclear to me whether the rank is as simple as biasing the original "All articles" rank toward more recent documents or if there is more involved here. Understandably, given competitive issues, Dejan did not want to chat me up on the details.
In any case, let me add a couple comments to my original post. First, I had not noticed that the "All articles" Google Scholar relevance rank is as good as it now seems to be until I played with the service again after seeing Dejan's post. The ordering is much better than I recalled. Some of what I think of as the best recent papers in the field were at or near the top of many searches I tried.
As for the new "Recent articles" feature that Dejan posted about, it is interesting to try the searches again ([personalization], [collaborative filtering], and [web search]) with that enabled.
On the [web search] query, I see that the Jeff Dean 2003 IEEE "Google Cluster Architecture" paper now is in the top results, a good find. And it is flattering to see that one of my recent papers is near the top for a "Recent articles" query for [collaborative filtering].
I have tended to prefer the old Citeseer over Google Scholar, mostly because Citeseer makes it particularly easy to download a copy of the papers, but I often get frustrated with the slowness and poor relevance rank in Citeseer. I will have to turn to Google Scholar more frequently.
We try to rank recent papers the way researchers do, by looking at the prominence of the author's and journal's previous papers, how many citations it already has, when it was written, and so on.On a search for [personalization], it was neat to see that the fifth result was a paper by Udi Manber and Ash Patel about personalization features on Yahoo.
On a search for [collaborative filtering], the first results appropriately are GroupLens papers, followed by an excellent Breese and Heckerman paper.
On a search for [web search], the Sergey Brin and Larry Page's paper gets the top result, followed by a paper from Steve Lawrence.
Great stuff. Very cool and very useful.
Update: As Dejan wrote in an update to his post and confirmed to me by e-mail and OR pointed out in the comments, the new feature is the "Recent articles" relevance rank. The "All articles" relevance rank (which I linked to in my examples above) is unchanged.
Hearing this, I think it is likely this feature is a response to the recent launch of Windows Live Academic and "order by date" features in that service. The Google Scholar "Recent articles" ranking is more complicated than just ordering by date, but it is unclear to me whether the rank is as simple as biasing the original "All articles" rank toward more recent documents or if there is more involved here. Understandably, given competitive issues, Dejan did not want to chat me up on the details.
In any case, let me add a couple comments to my original post. First, I had not noticed that the "All articles" Google Scholar relevance rank is as good as it now seems to be until I played with the service again after seeing Dejan's post. The ordering is much better than I recalled. Some of what I think of as the best recent papers in the field were at or near the top of many searches I tried.
As for the new "Recent articles" feature that Dejan posted about, it is interesting to try the searches again ([personalization], [collaborative filtering], and [web search]) with that enabled.
On the [web search] query, I see that the Jeff Dean 2003 IEEE "Google Cluster Architecture" paper now is in the top results, a good find. And it is flattering to see that one of my recent papers is near the top for a "Recent articles" query for [collaborative filtering].
I have tended to prefer the old Citeseer over Google Scholar, mostly because Citeseer makes it particularly easy to download a copy of the papers, but I often get frustrated with the slowness and poor relevance rank in Citeseer. I will have to turn to Google Scholar more frequently.
eBay's growth and competitive threats
Robert Hof at BusinessWeek writes about "eBay's Diminished Expectations" and competitive threats to eBay. An excerpt:
Update: Reports leak out that eBay is considering teaming up with Microsoft or Yahoo against Google.
Update: Five months later, a BusinessWeek article reports the eBay "magic is gone ... Shoppers are simply not buying all the inventory anymore. Some items languish without a single bidder. Many shoppers opt for other sites including Amazon.com, use sophisticated search engines such as Google and Yahoo!, or head to store sites directly."
Update: Eighteen months later, Saul Hansell at the NYT reports that "sellers have become disenchanted with eBay" and "eBay is looking to reduce its listing fees and raise its final value fees ... [but] given the depth of the anger against the company, I wonder if that will be enough."
Some sellers have reported for some time that their profit margins on eBay are eroding. That's one factor that has prompted some of them to move some of their inventory to other marketplaces, such as Amazon.com, Overstock.com, and Google Base.See also my previous posts, "Google and eBay pursue sellers", "Disintermediation of eBay", and "eBay's search for sellers".
What's more, search giant Google is coming on strong. Its free Google Base listings service, coupled with a new payment system, threatens to undercut eBay by offering merchants a cheaper venue on which to sell.
Update: Reports leak out that eBay is considering teaming up with Microsoft or Yahoo against Google.
Update: Five months later, a BusinessWeek article reports the eBay "magic is gone ... Shoppers are simply not buying all the inventory anymore. Some items languish without a single bidder. Many shoppers opt for other sites including Amazon.com, use sophisticated search engines such as Google and Yahoo!, or head to store sites directly."
Update: Eighteen months later, Saul Hansell at the NYT reports that "sellers have become disenchanted with eBay" and "eBay is looking to reduce its listing fees and raise its final value fees ... [but] given the depth of the anger against the company, I wonder if that will be enough."
Tuesday, April 18, 2006
Findory Mobile
Findory just launched a simplified interface, Findory Mobile, designed for the smaller screens on mobile devices. To use it, just point your mobile's web browser to mobile.findory.com.
There were quite a few people using the normal Findory.com websites on mobile devices, which already displays fairly well, but it is a bit clumsier than it should be.
Findory Mobile is a clean and simple page. Content is stripped down. Navigation is at the bottom. It is quick and easy to skim top headlines. There is also a new feature, a [more like this] button, that adds more personalized articles to the page without enduring the lengthy page load times of other websites.
Just like the normal Findory.com site, Findory Mobile learns from the news you read, bubbling the most interesting articles to the top, focusing your attention on news you might otherwise miss.
Break out your Treo or your cell phone and give it a whirl!
There were quite a few people using the normal Findory.com websites on mobile devices, which already displays fairly well, but it is a bit clumsier than it should be.
Findory Mobile is a clean and simple page. Content is stripped down. Navigation is at the bottom. It is quick and easy to skim top headlines. There is also a new feature, a [more like this] button, that adds more personalized articles to the page without enduring the lengthy page load times of other websites.
Just like the normal Findory.com site, Findory Mobile learns from the news you read, bubbling the most interesting articles to the top, focusing your attention on news you might otherwise miss.
Break out your Treo or your cell phone and give it a whirl!
An increase in advertising online
Paul Kedrosky points out that the big marketing budgets of consumer product companies finally are starting to shift online.
Most notable is that Anheuser-Busch will be doing 5% of total ad spend online and Pepsi 5-10%, significant increases from their past budgets.
As Paul says:
Update: Anick Jesdanun at the AP reports that "online advertising set a new record of $12.5 billion last year, a 30 percent increase from the previous high of $9.63 billion in 2004."
Most notable is that Anheuser-Busch will be doing 5% of total ad spend online and Pepsi 5-10%, significant increases from their past budgets.
As Paul says:
To put it in context, packaged goods companies accounted for 11% of the 145-billion U.S. ad market in 2005 -- but they spent just 1.6% of the ad money online last year.Old habits die hard, but I have surprised by how long it has taken for these massive brand marketing budgets to shift from offline, where it is difficult to track the impact, to online, where measurement and optimization are easier.
There is ... a lot of room for a major ad-dollar budget shift.
Update: Anick Jesdanun at the AP reports that "online advertising set a new record of $12.5 billion last year, a 30 percent increase from the previous high of $9.63 billion in 2004."
TechCrunch reviews mapping sites
Frank Gruber at TechCrunch posts an excellent and detailed review of the mapping services available, covering Google Maps, Windows Live (aka MSN) Local Maps, Yahoo Maps, Ask.com Maps, and the venerable Mapquest (but not A9 Maps).
I agree with Frank that the brand spankin' new Yahoo Maps Beta, with its fast and spiffy Flash interface, is the best of the lot. If you haven't tried it, you should. It's clean, easy to use, speedy, and has some nice extra features. It's also convenient that, unlike Google Maps, Yahoo Maps Beta covers international destinations.
My only issue with Yahoo Maps Beta is that it is not yet the default on Yahoo, so I usually end up using Google Maps. I'm just too lazy to manually go to the special Yahoo Maps Beta site. Darn lazy users. I hope Yahoo moves the new interface out of beta soon so everyone can benefit.
[via Barry Schwartz]
Update: Eight days later, Google Maps launches for several countries in Europe. The satellite view of the Eiffel Tower is jaw-dropping.
I agree with Frank that the brand spankin' new Yahoo Maps Beta, with its fast and spiffy Flash interface, is the best of the lot. If you haven't tried it, you should. It's clean, easy to use, speedy, and has some nice extra features. It's also convenient that, unlike Google Maps, Yahoo Maps Beta covers international destinations.
My only issue with Yahoo Maps Beta is that it is not yet the default on Yahoo, so I usually end up using Google Maps. I'm just too lazy to manually go to the special Yahoo Maps Beta site. Darn lazy users. I hope Yahoo moves the new interface out of beta soon so everyone can benefit.
[via Barry Schwartz]
Update: Eight days later, Google Maps launches for several countries in Europe. The satellite view of the Eiffel Tower is jaw-dropping.
Monday, April 17, 2006
What will become of A9?
Now that CEO Udi Manber left, what will become of A9?
My understanding is that Amazon created A9 around Udi and his vision for search. If true, the loss of Udi likely will change A9 and its direction, especially since traffic growth is flat with little signs of traction.
Anyone have any thoughts what they might do? What they should do?
A9 gets its search results from Google, so they may have relatively little investment in web search. Where will they go? I could see a range of possibilities.
Rather than focus on web search, perhaps A9 could switch to shopping metasearch. Shopping metasearch would focus on where Amazon has the most expertise -- shopping -- while still partially defending Amazon against the threat of disintermediation by Google and other web search giants.
A9 could switch to focusing on AdWords and AdSense-like advertising, building on the success of Amazon Associates. A9 would compete with Google not on web search, where Google has a strong advantage, but on advertising, where Amazon has its massive catalog and experience selling products to leverage.
A9 could focus on web services, emphasizing selling Amazon's shopping search technology to other e-commerce companies, much like Google does for intranet search with Google Enterprise. I suspect this would be a modest business for Amazon, but it would fit with Amazon's recent push for web services.
A9 could jump forward to execute on massively distributed web search, an area few others are exploring that is one approach toward opening up the "invisible web". To do this, A9 would have to expand its "search columns" to accessing hundreds of thousands of databases, then tackle the challenging problem of intelligently determining which available databases are most likely to provide the best answer to a given query (since you can only query a small subset of the databases in real time). Tough nut to crack, but this space is wide open.
A9 could fade away from lack of momentum and interest, like Auctions, zShops, web-based calendaring (PlanetAll), metashopping search (Junglee), and other saddening past Amazon experiments. I fear this may be quite likely.
What do you think will happen? Do you have thoughts on other likely directions for A9?
Update: One year later, A9 has suffered an 80%+ drop in traffic. It appears "fade away" may turn out to be the correct prediction.
My understanding is that Amazon created A9 around Udi and his vision for search. If true, the loss of Udi likely will change A9 and its direction, especially since traffic growth is flat with little signs of traction.
Anyone have any thoughts what they might do? What they should do?
A9 gets its search results from Google, so they may have relatively little investment in web search. Where will they go? I could see a range of possibilities.
Rather than focus on web search, perhaps A9 could switch to shopping metasearch. Shopping metasearch would focus on where Amazon has the most expertise -- shopping -- while still partially defending Amazon against the threat of disintermediation by Google and other web search giants.
A9 could switch to focusing on AdWords and AdSense-like advertising, building on the success of Amazon Associates. A9 would compete with Google not on web search, where Google has a strong advantage, but on advertising, where Amazon has its massive catalog and experience selling products to leverage.
A9 could focus on web services, emphasizing selling Amazon's shopping search technology to other e-commerce companies, much like Google does for intranet search with Google Enterprise. I suspect this would be a modest business for Amazon, but it would fit with Amazon's recent push for web services.
A9 could jump forward to execute on massively distributed web search, an area few others are exploring that is one approach toward opening up the "invisible web". To do this, A9 would have to expand its "search columns" to accessing hundreds of thousands of databases, then tackle the challenging problem of intelligently determining which available databases are most likely to provide the best answer to a given query (since you can only query a small subset of the databases in real time). Tough nut to crack, but this space is wide open.
A9 could fade away from lack of momentum and interest, like Auctions, zShops, web-based calendaring (PlanetAll), metashopping search (Junglee), and other saddening past Amazon experiments. I fear this may be quite likely.
What do you think will happen? Do you have thoughts on other likely directions for A9?
Update: One year later, A9 has suffered an 80%+ drop in traffic. It appears "fade away" may turn out to be the correct prediction.
Saturday, April 15, 2006
Kill Google, Vol. 3
In a comment to my previous post, Anil Dharni said:
AdSense is now about half of Google's revenue and their future growth. Microsoft should strangle Google's air supply, their revenue stream.
Targeting ads well to content is hard. Google AdSense does not do a great job of it yet. Advertising should be useful, relevant, and interesting content -- information about products and services you want to hear about -- and it is not. There is a real opportunity here to do it better.
This is where I think Microsoft should focus the majority of its attention.
Microsoft should have its tech and R&D teams develop better targeting through personalization, segmentation, real-time optimization, and content analysis.
Microsoft should use its size to make deals that allow it to offer much deeper ad inventory (e.g. ads for individual products at Amazon or eBay, individual articles at a magazine, specific homes at a real estate broker, or specific video content from NBC).
Microsoft should use its market power to be the exclusive ad provider for large sites like major newspapers, big online magazines, and traffic giants like AOL or MySpace.
Microsoft should use its cash reserves to make being an advertising provider unprofitable for others, lowering ad broker revenue share to near 0%.
Microsoft should ruin AdSense, undermine it, destroy it. There should be no business in AdSense-like products for anyone.
Now, yes, experimenting with new tools, building MSN search, and doing R&D is a good idea. Microsoft may come up with a game changer, perhaps even one that Google and Yahoo cannot immediately copy.
But I think the strategy to win is different. If Microsoft wants to win, it should play to its strengths. It should not seek to change the game. It should seek to end the game.
See also my previous posts, "Kill Google, Vol. 2" and "Kill Google, Vol. 1".
If you want to be beat Google, would you like to throw more manpower to beat Google's search algorithms or would you rather try and change the search paradigm.If I want to beat Google? I would throw everything I have got at an AdSense killer.
AdSense is now about half of Google's revenue and their future growth. Microsoft should strangle Google's air supply, their revenue stream.
Targeting ads well to content is hard. Google AdSense does not do a great job of it yet. Advertising should be useful, relevant, and interesting content -- information about products and services you want to hear about -- and it is not. There is a real opportunity here to do it better.
This is where I think Microsoft should focus the majority of its attention.
Microsoft should have its tech and R&D teams develop better targeting through personalization, segmentation, real-time optimization, and content analysis.
Microsoft should use its size to make deals that allow it to offer much deeper ad inventory (e.g. ads for individual products at Amazon or eBay, individual articles at a magazine, specific homes at a real estate broker, or specific video content from NBC).
Microsoft should use its market power to be the exclusive ad provider for large sites like major newspapers, big online magazines, and traffic giants like AOL or MySpace.
Microsoft should use its cash reserves to make being an advertising provider unprofitable for others, lowering ad broker revenue share to near 0%.
Microsoft should ruin AdSense, undermine it, destroy it. There should be no business in AdSense-like products for anyone.
Now, yes, experimenting with new tools, building MSN search, and doing R&D is a good idea. Microsoft may come up with a game changer, perhaps even one that Google and Yahoo cannot immediately copy.
But I think the strategy to win is different. If Microsoft wants to win, it should play to its strengths. It should not seek to change the game. It should seek to end the game.
See also my previous posts, "Kill Google, Vol. 2" and "Kill Google, Vol. 1".
Friday, April 14, 2006
MSN Answers coming?
Olga Kharif at BusinessWeek reports that Microsoft will be launching a question-and-answer tool and more aggressively pursuing social search:
I tried asking a three non-trivial questions on Yahoo Answers yesterday. Unfortunately, as I expected, the answers I received are half-assed, sloppy, and useless.
I still think Ask SVP Jim Lanzone had it right when he suggested that there is little incentive for people to answer hard questions in these tools and that, for easy questions, it is "usually just faster and easier for people to search normally ... than to submit a question to the community and wait for an answer."
Popping up to a higher level, I find it curious that MSN is going down this path. Not only are they doing a knock-off of Yahoo Answers, but also BusinessWeek suggests that they intend to go after social search, a Yahoo My Web 2.0 knock-off perhaps.
I had thought that MSN's search strategy was to provide easy-to-use, more powerful tools for search, but these recent moves suggest that MSN may also be pursuing social search, trying to exploit the power of their community to improve search like Yahoo seeks to do.
And this makes me wonder if Microsoft has shifted its sights from targeting Google to targeting Yahoo. Is Yahoo an easier target than Google? Is Yahoo vulnerable? Does MSN have more to gain by going after the #2 player than the #1?
See also Danny Sullivan's excellent comments on the BusinessWeek article.
Update: It appears Yahoo Answers deletes questions that fail to get good answers -- a bit annoying, but probably a good idea -- so the link above to my three questions may no longer work. The questions were about Google's AdSense revenues and the traffic on Yahoo Answers and Yahoo MyWeb. The answers were useless, as I expected. This is most likely because a high quality answer to the questions would have required some effort and expertise. There is little incentive for people with expertise to expend effort on Yahoo Answers.
Update: Barry Schwartz reports that the Yahoo Answers knock-off, MSN Answers, changed its name to Windows Live QnA and is now in closed beta.
Microsoft plans to unveil a question-and-answer social-search tool in the coming months ... The feature will let users direct questions to a specific universe, such as a group of friends, rather than to get automated lists of results from a generic search engine.Coincidentally, I was just talking yesterday with someone at MSN about Yahoo Answers. He surprised me by saying that Yahoo Answers is effective and successful. He claimed that there is a lot of crap on Yahoo Answers, but, if you ask a question, you will get a good answer quickly. He encouraged me to try it again.
I tried asking a three non-trivial questions on Yahoo Answers yesterday. Unfortunately, as I expected, the answers I received are half-assed, sloppy, and useless.
I still think Ask SVP Jim Lanzone had it right when he suggested that there is little incentive for people to answer hard questions in these tools and that, for easy questions, it is "usually just faster and easier for people to search normally ... than to submit a question to the community and wait for an answer."
Popping up to a higher level, I find it curious that MSN is going down this path. Not only are they doing a knock-off of Yahoo Answers, but also BusinessWeek suggests that they intend to go after social search, a Yahoo My Web 2.0 knock-off perhaps.
I had thought that MSN's search strategy was to provide easy-to-use, more powerful tools for search, but these recent moves suggest that MSN may also be pursuing social search, trying to exploit the power of their community to improve search like Yahoo seeks to do.
And this makes me wonder if Microsoft has shifted its sights from targeting Google to targeting Yahoo. Is Yahoo an easier target than Google? Is Yahoo vulnerable? Does MSN have more to gain by going after the #2 player than the #1?
See also Danny Sullivan's excellent comments on the BusinessWeek article.
Update: It appears Yahoo Answers deletes questions that fail to get good answers -- a bit annoying, but probably a good idea -- so the link above to my three questions may no longer work. The questions were about Google's AdSense revenues and the traffic on Yahoo Answers and Yahoo MyWeb. The answers were useless, as I expected. This is most likely because a high quality answer to the questions would have required some effort and expertise. There is little incentive for people with expertise to expend effort on Yahoo Answers.
Update: Barry Schwartz reports that the Yahoo Answers knock-off, MSN Answers, changed its name to Windows Live QnA and is now in closed beta.
Wednesday, April 12, 2006
Findory traffic growth Q1 2006
Findory.com has been live since January of 2004. The website has grown rapidly over the last two years.
Every quarter since Q4 2004, I have posted charts showing Findory's growth. The Q1 2006 numbers are now in:
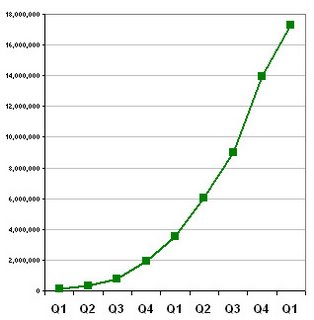
As in the previous posts ([1] [2] [3] [4] [5]), the data show total "viewed hits" (hits excluding robots and redirects) for each quarter. Viewed hits for March 2006 were 5.8M, viewed page views were 4.7M. Total hits (including robots, redirects, etc.) on the Findory.com webservers in March 2006 were 9.5M.
The chart shows Findory growth slowing a bit in Q1 2006, down to about 8% per month (24% per quarter) from the 16% per month of the previous quarter.
The slower growth is not surprising. Development at Findory has been clipped and PR efforts reduced. In addition, my analysis of the effectiveness of our (tiny) advertising budget showed it was converting poorly, so I decided to eliminate it. All of these could impact Findory growth rates.
Findory was cash flow positive for all of Q1 2006. On top of our continuing growth, this is good news. The extra cash Findory is generating is modest, sufficient for an additional server or two for the cluster, but definitely nice to have.
Looking toward the future, I would like to see Findory move into other products (pictures, video, podcasts), further develop our personalized advertising, work on a more mature version of our alpha personalized web search, improve support for mobile devices, add additional customization features for power users, expand the breadth of our news and blog crawls, and offer internationalized versions (German, French, Spanish, Japanese, Chinese) of Findory.
There is much to do!
Every quarter since Q4 2004, I have posted charts showing Findory's growth. The Q1 2006 numbers are now in:
As in the previous posts ([1] [2] [3] [4] [5]), the data show total "viewed hits" (hits excluding robots and redirects) for each quarter. Viewed hits for March 2006 were 5.8M, viewed page views were 4.7M. Total hits (including robots, redirects, etc.) on the Findory.com webservers in March 2006 were 9.5M.
The chart shows Findory growth slowing a bit in Q1 2006, down to about 8% per month (24% per quarter) from the 16% per month of the previous quarter.
The slower growth is not surprising. Development at Findory has been clipped and PR efforts reduced. In addition, my analysis of the effectiveness of our (tiny) advertising budget showed it was converting poorly, so I decided to eliminate it. All of these could impact Findory growth rates.
Findory was cash flow positive for all of Q1 2006. On top of our continuing growth, this is good news. The extra cash Findory is generating is modest, sufficient for an additional server or two for the cluster, but definitely nice to have.
Looking toward the future, I would like to see Findory move into other products (pictures, video, podcasts), further develop our personalized advertising, work on a more mature version of our alpha personalized web search, improve support for mobile devices, add additional customization features for power users, expand the breadth of our news and blog crawls, and offer internationalized versions (German, French, Spanish, Japanese, Chinese) of Findory.
There is much to do!
Wednesday, April 05, 2006
MyLifeBits, Memex, and Google Desktop Search
Gary Price recently pointed to an interesting new MyLifeBits technical report, "MyLifeBits: A Personal Database for Everything".
The MyLifeBits project at Microsoft Research is an attempt to make most aspects of a person's work and life experiences searchable. MyLifeBits captures every e-mail, every web page visited, documents read, every phone call, every bit of music, every photo. They even started taking video of the researcher's daily life and making that searchable.
As you might expect and as discussed in the paper, the project is inspired by Vannevar Bush's Memex.
The paper was a fun read, but I was shocked when I discovered they initially expected users to spend time organizing and cataloguing all this information. Unsurprisingly, they found that unworkable. Some excerpts:
I have to say, there is no way I would organize or tag this kind of data manually. The gigabytes of photos I have on my computer look like the "big shoebox" mentioned in the paper, and, if changing that requires any effort from me, they will never look like anything else.
In general, while many would get value from something that searched over all the data generated in their daily life, I suspect few would be willing to do substantial work to get those benefits.
In fact, I find that Google Desktop Search is approaching what I need. It already finds information about who I have e-mailed, meetings I had, documents I read, and web pages I visited.
It would be marginally more useful if it searched every phone conversation (after dealing with legal issues and improving speech to text), every photo (after improving face and object recognition), and every TV show and movie (legal issues, speech to text). But only marginally.
Having searchable video of my daily life (360 degree video 24 hours/day) might also be useful, but the privacy, legal, and technical issues there are extreme.
So, this has me wondering. How close is Google Desktop Search to the low hanging fruit, the most useful parts, of Memex?
After reading the MyLifeBits paper, I am wondering if the endpoint envisioned in that paper is really all that desirable. Perhaps we are closer than we might think to the parts of Memex we really need?
See also the Microsoft Research project, "Stuff I've Seen".
See also my Oct 2004 post, "Google Memex".
The MyLifeBits project at Microsoft Research is an attempt to make most aspects of a person's work and life experiences searchable. MyLifeBits captures every e-mail, every web page visited, documents read, every phone call, every bit of music, every photo. They even started taking video of the researcher's daily life and making that searchable.
As you might expect and as discussed in the paper, the project is inspired by Vannevar Bush's Memex.
The paper was a fun read, but I was shocked when I discovered they initially expected users to spend time organizing and cataloguing all this information. Unsurprisingly, they found that unworkable. Some excerpts:
With large quantities of information, users are not just unwilling to classify, but are in fact unable to do it ....In the future work appendix to the paper, the authors describe how it would reduce the work required for classification and cataloguing all the accumulated data if they had automatic speech to text for audio and video and face and object recognition for images and video.
Even with convenient classifications and labels ready to apply, we are still asking the user to become a filing clerk -- manually annotating every document, email, photo, or conversation.
We have worked on improving the tools, and to a degree they work, but to provide higher coverage of the collection more must be done automatically ....
Even capture itself must be more automatic on this scale so that the user isn't forced to interrupt their normal life in order to become their own biographer.
I have to say, there is no way I would organize or tag this kind of data manually. The gigabytes of photos I have on my computer look like the "big shoebox" mentioned in the paper, and, if changing that requires any effort from me, they will never look like anything else.
In general, while many would get value from something that searched over all the data generated in their daily life, I suspect few would be willing to do substantial work to get those benefits.
In fact, I find that Google Desktop Search is approaching what I need. It already finds information about who I have e-mailed, meetings I had, documents I read, and web pages I visited.
It would be marginally more useful if it searched every phone conversation (after dealing with legal issues and improving speech to text), every photo (after improving face and object recognition), and every TV show and movie (legal issues, speech to text). But only marginally.
Having searchable video of my daily life (360 degree video 24 hours/day) might also be useful, but the privacy, legal, and technical issues there are extreme.
So, this has me wondering. How close is Google Desktop Search to the low hanging fruit, the most useful parts, of Memex?
After reading the MyLifeBits paper, I am wondering if the endpoint envisioned in that paper is really all that desirable. Perhaps we are closer than we might think to the parts of Memex we really need?
See also the Microsoft Research project, "Stuff I've Seen".
See also my Oct 2004 post, "Google Memex".
Phishing and stopping phishing
Bruce Schneier points to a interesting paper out of Harvard and Berkeley called "Why Phishing Works" (PDF).
It is a light paper that reports on a usability study where people tried to determine whether certain websites were spoofs or real. The failure rates were dismally high even for expert computer users.
The paper concludes by calling for loud, obvious indicators that a site may be fake placed directly in the user's center of attention. Anything else, the paper says, is likely to be ignored.
That is the path new anti-phishing tools appear to be taking. The anti-phishing warning in GMail, for example, is loud and obvious. The planned Microsoft Phishing Filter for IE7 also looks like it will make the warnings hard to ignore by refusing to display spoofed websites.
Update: Justin Voskuhl at Google Kirkland just announced on the official Google Blog that the latest version of the Google Toolbar for Firefox now has an integrated anti-phishing feature.
It is a light paper that reports on a usability study where people tried to determine whether certain websites were spoofs or real. The failure rates were dismally high even for expert computer users.
The paper concludes by calling for loud, obvious indicators that a site may be fake placed directly in the user's center of attention. Anything else, the paper says, is likely to be ignored.
That is the path new anti-phishing tools appear to be taking. The anti-phishing warning in GMail, for example, is loud and obvious. The planned Microsoft Phishing Filter for IE7 also looks like it will make the warnings hard to ignore by refusing to display spoofed websites.
Update: Justin Voskuhl at Google Kirkland just announced on the official Google Blog that the latest version of the Google Toolbar for Firefox now has an integrated anti-phishing feature.
Tuesday, April 04, 2006
Google Related Links in Google Labs
Philipp Lenssen points out that the Google Related Links widget -- a Javascript block that shows links to related searches, web pages, or news stories -- is now available to everyone in Google Labs.
I thought the news version was kind of interesting, a little like Findory Inline or the BBC's Newstracker feature.
More on Google Related Links from Danny Sullivan, Tara Calishain, and Nathan Weinberg.
Update: Fifteen months later, Google shuts down their Related Links widget. Google Blogoscoped is hosting a discussion about it in their forum.
I thought the news version was kind of interesting, a little like Findory Inline or the BBC's Newstracker feature.
More on Google Related Links from Danny Sullivan, Tara Calishain, and Nathan Weinberg.
Update: Fifteen months later, Google shuts down their Related Links widget. Google Blogoscoped is hosting a discussion about it in their forum.
Monday, April 03, 2006
Claria and PersonalWeb
Claria, a company infamous for unpleasant adware products, apparently is trying to move into personalization of content.
Mario Sgambelluri interviews Claria EVP/CMO Scott Eagle about Claria's plans. Some excerpts:
On the one hand, it good to see enthusiasm for personalization of content and information. Scott Eagle is saying that personalization can help readers find interesting content they wouldn't find on their own, all without any effort. The focus on the reader and helping the reader is promising.
On the other hand, I am concerned to see this interest in personalization from a company with a reputation for developing intrusive adware products. I am worried that having a known adware vendor working in personalization of information could push users toward distrusting all personalized websites, setting back development in the field for years.
See also articles on Claria PersonalWeb in BusinessWeek, New York Times, SiliconBeat, and TechDirt.
Mario Sgambelluri interviews Claria EVP/CMO Scott Eagle about Claria's plans. Some excerpts:
PersonalWeb [brings] the content that a user wants together in one place -- creating a customized web page based on their online interests -- automatically and anonymously.Reading this interview, I have two reactions.
PersonalWeb learns what topics an individual user is interested in ... [and] recommends new content that matches their interests -- content they may never have discovered otherwise.
As personal interests and favorite websites change over time, the PersonalWeb page also changes -- remaining totally personalized with content relevant to each individual consumer.
PersonalWeb creates a customized home page tailored to a user's unique interests -- automatically. There is nothing for a user to set up or maintain.
Less than 10 percent of consumers take the time to manually configure or personalize a home page. Our internal research shows that the other 90 percent want the benefits of personalization but either don't know how, are too busy to bother, or feel that the page will become outdated if they don't continually update their preferences.
With so much happening online in terms of the vast amount of content available to discover, it can be difficult for consumers to easily find and enjoy the content most relevant to them. The solution is technology that understands your ever-changing interests and automatically brings you what you like most.
On the one hand, it good to see enthusiasm for personalization of content and information. Scott Eagle is saying that personalization can help readers find interesting content they wouldn't find on their own, all without any effort. The focus on the reader and helping the reader is promising.
On the other hand, I am concerned to see this interest in personalization from a company with a reputation for developing intrusive adware products. I am worried that having a known adware vendor working in personalization of information could push users toward distrusting all personalized websites, setting back development in the field for years.
See also articles on Claria PersonalWeb in BusinessWeek, New York Times, SiliconBeat, and TechDirt.
Sunday, April 02, 2006
Early Amazon: Recommendations
The first recommendation feature at Amazon.com, BookMatcher, did not work very well. It required 20+ ratings to make recommendations. The recommendations leaned heavily toward bestsellers. The recommendations were often uninteresting, spurious, or obvious. Adding insult to injury, the system was always in danger of falling down under load.
As another side project (see "Early Amazon: Inventory cache"), I started working on a replacement. I wanted the recommendation engine to be fast, scalable, and able to work from just a couple ratings or purchases.
This was not what I was supposed to be doing, mind you.
I never got a chance to work on the BookMatcher project. I wasn't supposed to be working on recommendations. There were other, official projects that consumed my normal waking hours.
This was something I did on the side. My twisted, geek idea of fun.
I hacked. I tested. I iterated. With time, I built something that worked well.
I showed it to a few other people. Right around then, there was a major redesign of the Amazon.com website. Before I knew it, I was rushing my little prototype out the door.
A talented engineering manager named Dwayne helped put a spiffy UI on top of the recommendation engine. We rolled it out with the other changes. The new feature was called "Instant Recommendations".
Bookmatcher and Instant Recommendations co-existed on the site for some time. Eventually, low traffic, performance problems, and poor recommendation quality caused BookMatcher to disappear.
Instant Recommendations expanded to take its place, and eventually formed the backbone for much of the personalization at Amazon.
Such a useful and valuable feature came from work I was never supposed to be doing. In there somewhere lies the secret to innovation.
As another side project (see "Early Amazon: Inventory cache"), I started working on a replacement. I wanted the recommendation engine to be fast, scalable, and able to work from just a couple ratings or purchases.
This was not what I was supposed to be doing, mind you.
I never got a chance to work on the BookMatcher project. I wasn't supposed to be working on recommendations. There were other, official projects that consumed my normal waking hours.
This was something I did on the side. My twisted, geek idea of fun.
I hacked. I tested. I iterated. With time, I built something that worked well.
I showed it to a few other people. Right around then, there was a major redesign of the Amazon.com website. Before I knew it, I was rushing my little prototype out the door.
A talented engineering manager named Dwayne helped put a spiffy UI on top of the recommendation engine. We rolled it out with the other changes. The new feature was called "Instant Recommendations".
Bookmatcher and Instant Recommendations co-existed on the site for some time. Eventually, low traffic, performance problems, and poor recommendation quality caused BookMatcher to disappear.
Instant Recommendations expanded to take its place, and eventually formed the backbone for much of the personalization at Amazon.
Such a useful and valuable feature came from work I was never supposed to be doing. In there somewhere lies the secret to innovation.
Subscribe to:
Posts (Atom)
